Lost generations: 1880-1990
Greatest generation: 1900-1920
Silent Generation: 1920-1940
Baby Boomers: 1940-1960
Generation X: 1960-1980
Millennials: 1980-2000
Generation Z: 2000
Lost generations: 1880-1990
Greatest generation: 1900-1920
Silent Generation: 1920-1940
Baby Boomers: 1940-1960
Generation X: 1960-1980
Millennials: 1980-2000
Generation Z: 2000
I thought this is a fiction, but it turned out to be a political satirical tale. It reminds me of the cultural revolution. It is astonishing that the author predicts the future event which happen in 1960s in the year 1940s. At that time it only alludes the Stalinist era of the Soviet Union. But history is reproduced.
Summary (from Wiki):
Old Major, the old boar on the Manor Farm, summons the animals on the farm together for a meeting, during which he refers to humans as “enemies” and teaches the animals a revolutionary song called “Beasts of England”. When Major dies, two young pigs, Snowball and Napoleon, assume command and consider it a duty to prepare for the Rebellion. The animals revolt and drive the drunken and irresponsible farmer Mr. Jones from the farm, renaming it “Animal Farm”. They adopt the Seven Commandments of Animalism, the most important of which is, “All animals are equal.”
Snowball teaches the animals to read and write, while Napoleon educates young puppies on the principles of Animalism. Food is plentiful, and the farm runs smoothly. The pigs elevate themselves to positions of leadership and set aside special food items, ostensibly for their personal health.
Some time later, several men attack Animal Farm. Jones and his men are making an attempt to recapture the farm, aided by several other farmers who are terrified of similar animal revolts. Snowball and the animals, who are hiding in ambush, defeat the men by launching a surprise attack as soon as they enter the farmyard. Snowball’s popularity soars, and this event is proclaimed “The Battle of the Cowshed”. It is celebrated annually with the firing of a gun, on the anniversary of the Revolution.
Napoleon and Snowball vie for pre-eminence. When Snowball announces his plans to modernize the farm by building a windmill, Napoleon has his dogs chase Snowball away and declares himself leader.
Napoleon enacts changes to the governance structure of the farm, replacing meetings with a committee of pigs who will run the farm. Through a young pig named Squealer, Napoleon claims credit for the windmill idea. The animals work harder with the promise of easier lives with the windmill. When the animals find the windmill collapsed after a violent storm, Napoleon and Squealer convince the animals that Snowball is trying to sabotage their project. Once Snowball becomes a scapegoat, Napoleon begins to purge the farm with his dogs, killing animals he accuses of consorting with his old rival. When some animals recall the Battle of the Cowshed, Napoleon (who was nowhere to be found during the battle) frequently smears Snowball as a collaborator of Jones’, while falsely representing himself as the hero of the battle. “Beasts of England” is replaced with an anthem glorifying Napoleon, who appears to be adopting the lifestyle of a man. The animals remain convinced that they are better off than they were under Mr. Jones.
Mr Frederick, one of the neighbouring farmers, attacks the farm, using blasting powder to blow up the restored windmill. Though the animals win the battle, they do so at great cost, as many, including Boxer the workhorse, are wounded. Despite his injuries, Boxer continues working harder and harder, until he collapses while working on the windmill. Napoleon sends for a van to take Boxer to the veterinary surgeon, explaining that better care can be given there. Benjamin, the cynical donkey who “could read as well as any pig”, notices that the van belongs to a knacker and attempts a futile rescue. Squealer quickly assures the animals that the van had been purchased from the knacker by an animal hospital, and the previous owner’s signboard had not been repainted. In a subsequent report, Squealer reports sadly to the animals that Boxer died peacefully at the animal hospital; the pigs hold a festival one day after Boxer’s death to further praise the glories of Animal Farm and have the animals work harder by taking on Boxer’s ways. However, the truth was that Napoleon had engineered the sale of Boxer to the knacker, allowing him and his inner circle to acquire money to buy whisky for themselves. (In 1940s England, one way for farms to make money was to sell large animals to a knacker, who would kill the animal and boil its remains into animal glue.)
Years pass, and the windmill is rebuilt along with construction of another windmill, which makes the farm a good amount of income. However, the ideals which Snowball discussed, including stalls with electric lighting, heating and running water are forgotten, with Napoleon advocating that the happiest animals live simple lives. In addition to Boxer, many of the animals who participated in the Revolution are dead, as is Farmer Jones, who died in another part of England. The pigs start to resemble humans, as they walk upright, carry whips, and wear clothes. The Seven Commandments are abridged to a single phrase: “All animals are equal but some animals are more equal than others”. Napoleon holds a dinner party for the pigs and local farmers, with whom he celebrates a new alliance. He abolishes the practice of the revolutionary traditions and restores the name “The Manor Farm”. As the animals look from pigs to humans, they realize they can no longer distinguish between the two.
At the age of 26, I am thinking about my death. Pursuing the truly meaningful life ahead of me, I am wondering what it should be like, considering that everyone has the same destiny: death. More painfully, what if I happen to suffer from mortal disease when I reach the successful peak point of my life?
Paul Kalanithi, a neurosurgeon who was diagnosed with lung cancer at 35, one year before he could finish his residency, wrote the book <When Breath Becomes Air>. It records the life he has since his childhood, before the diagnose; and the struggle he experienced till death.
I am totally moved by this book. It shows what a man truly think about before his death. Knowing when to die, determines what is important to do before death.
There must be a way, I thought, that the language of life as experienced – of passion, of hunger, of love – bore some relationship, however convoluted, to the language of neurons, digestive tracts, and heartbeats.
Reading books and answering multiple-choice questions bore little resemblance to taking actions, with its concomitant responsibility.
I was a prophet returning from the mountaintop with news of joyous new covenant!
A match flickers but does not light.
At those critical junctures, the questions is not simply whether to live or die but what kind of life is worth living.
Concomitant with the enormous responsibilities they shouldered, neurosurgeons were also masters of many fields: neurosurgeons were also masters of many fields: neurosurgery, ICU medicine, neurology, radiology.
Over the next seven years of training, we should grow from bearing witness to medical dramas to becoming leading actors in them.
But in residency, something else was gradually unfolding. In the midst of this endless barrage of head injuries, I begin to suspect that being so close to the fiery light of such moments only blinded me to their nature, like trying to learn astronomy by starting directly at the sun. I was not yet with patients in their pivotal moments, I was merely at those pivotal moments. I observed a lot of suffering; worse, I become inured to it. Drowning, even in blood, one adapts, learns to float, to swim, even to enjoy life, bonding with the nurses, doctors, and others who are clinging to the same raft, caught in the same tide.
I could see the enormousness of the choice she faced dwindle into a difficult but understandable decision. I had met her in a space where she was a person, instead of a problem to be solved.
Sometimes the news so shocks the mind that the brain suffers an electrical short.
A tureen of tragedy was best allotted by the spoonful.
I came to believe that it is irresponsible to be more precise than you can be accurate.
Openness to human relationality does not mean revealing grand truths from the apse; it means meeting patients where they are, in the narthex or nave, and bringing them as far as you can.
I could see that there were two strategies to cutting the time short, perhaps best exemplified by the tortoise and the hare. The hare moves as fast as possible, hands a blur, instruments clattering, falling to the floor; the skin slops open like a curtain, the skull flap is on the tray before the bone dust settles. As a result, the opening might need expanded a centimeter here or there because it’s not optimally placed. The tortoise, on the other hand, proceeds deliberately, with no wasted movements, measuring twice, cutting once. No step of the operation needs revisiting; everything moves in a precise, orderly fashion. If the hare makes too many minor missteps and has to keep adjusting, the tortoise wins. If the tortoise spends too much time planning each step, the hare wins.
A sigh, and Earth continued to rotate back towards the sun.
I searched for a question to bring understanding. None was forthcoming. I could only imagine the overwhelming guilt, like a tidal wave, that had lifted him up and off that building.
Lucy and I both felt that life wasn’t about avoiding suffering.
Years ago, it had occurred to me that Darwin and Nietzsche agreed on one thing: the defining characteristic of the organism is striving.
In vitro
Moral duty has weight things that have weight have gravity, and so the duty to bear mortal responsibility pulled me back into the operating room.
The tricky part of illness is that, as you go through it, your values are constantly changing. You try to figure out what matters to you, and then you keep figuring it out. It felt like someone had taken away my credit card and I was having to learn how to budget. You may decide you want to learn how to budget. You can decide you want to spend your time working as a neurosurgeon, but two months later, you may feel differently. Two months after that, you may want to learn to play the saxophone or devote yourself to the church. Death may be a one-time event, but living with terminal illness is a process.
It struck me that I had traversed the five stages of grief — Denial -> Anger -> Bargaining -> Depression –> Acceptance cliché.
I had gone from being unable to believe I could be surgeon to being one, a transformation that carried the force of religious conversion.
Every trainee aspires to this goal; almost none make it.
The physician’s duty is not to stave off death or return patients to their old lives, but to take into our arms a patient and family whose lives have disintegrated and work until they can stand back up and face, and make sense of, their own existence.
Yet the paradox is that scientific methodology is the product of human hands and thus cannot reach some permanent truth. We build scientific theories to organize and manipulate the world, to reduce phenomena into manageable units. Science is based on reproducibility and manufactured objectivity. As strong as that makes its ability to generate claims, it also makes scientific knowledge inapplicable to the existential, visceral nature of human life, which is unique and subjective and unpredictable. Science may provide the most useful way to organize empirical, reproducible data, but its power to do so is predicated on its inability to grasp the most central aspects of human life: hope, fear, love, hate, beauty, envy, honor, weakness, striving, suffering, virtue.
The main message of Jesus, I believed, is that mercy trumps justice every time.
Human knowledge is never contained in one person. It grows from the relationships we create between each other and the world, and still it is never complete.
One sows and another reaps.
My life up until my illness could be understood as the linear sum of my choices.
There would be so many absences in Lucy’s and my daughter’s life – If this was as present as I could be, then so be it.
Graham Greene once said that life was lived in the first twenty years and the remainder was just reflection.
Money, status, all the vanities the preacher of Ecclesiastes described hold so little interest: a chasing after wind, indeed.
Paul’s decision not to avert his eyes from death epitomizes a fortitude we don’t celebrate enough in our death-avoidant culture.
The way forward would seem obvious, if only I knew how many months or years I had left. Tell me three months, I’d spend time with family. Tell me one year, I’d write a book. Give me ten years, I’d get back to treating diseases. The truth that you live one day at a time didn’t help: What was I supposed to do with that day?
There is only one month before SC deadline. I don’t know if I can make it, but I will try my best effort.
I felt a lot of pressure due to 5-year normal graduation duration for a PhD student. It is already the second semester for my 4th year, or senior year mapping to an undergraduate, but I still hang somewhere and somewhat confused about my future. Where am I going to end up with? In academia, or in industry? Stay here, or go back to my home country?
My boss is not taking care of me as well as before. He is just interested in applying for funding and doing Massive Open Online Course (MOOC). I have to manage myself and seek help from a postdoc in our group. At this time point, I get to know what a real PhD student should work like. You have to find your idea, start your own project, prove the concept by publications. No one else, except yourself, can actually strive every day and night towards your own goal.
I am a little overwhelmed with research/study/life balance now. My English still sucks, but I don’t even spend time reading English news. I cannot follow my passion to go to gym every day, because I feel otherwise I don’t have enough energy to do my daily research. As the deadline of SC is approaching, the atmosphere is more intensive.
Such is life. No solution to it yet. But I am kind of looking forward to the wonderful vacation trip after the deadline. Hope everything will be fine.
I felt the high altitude sickness on my first-day arrival in Salt Lake City. Luckily I am still young, and I am quickly getting used to the low atmosphere pressure…
Church Architecture of Mormons (The Church of Jesus Christ of Latter-day Saints):


Utah Capitol is quite similar to U.S. capitol, or Texas Capitol

We went hiking on the first Monday.

On our way, we ran into two/three moose:


I like the pink sunshine pouring on the mountain when sunset. This is captured during our way back to our parking lot. It is quite chilly even it is only around 4pm.
It snowed on Wednesday night! This is the first time I have seen since 2014, I guess.


On my last afternoon in SLC, I rented a car and drove to Antelope Island state park.


I like the beautiful scene of Great Salt Lake.

also the mountains and the grassland nearby.



After the first run, the performance drops.
Theoretically, after the first run, the cache becomes hot, and the JIT should work. However, the cycle number on macro-kernel/micro-kernel, and the GFLOPS performance are all decreasing.
The first run looks normal. It has similar performance with reference implementation. So that means the compiler for the assembly should work. The only possible reason, I can guess, is that A, B, C, packA or packB are not written back to the real “memory”, while the second run starts. So there are some latencies there. However, there are no such issues in BLIS.
Looking at BLIS packm implementations, it actually requests the packing buffer from the memory pool. BLIS has its own memory manager. However, my implementation just malloc in the beginning, but free in the end. For each run, it has to malloc again, and write/read that new allocated buffer. Maybe that’s the reason the performance drops after the first run.
I just do a quick and dirty trick to fix it. For the first run, I allocate the packing buffer, but don’t free it in the end. The second run just reuses this packing buffer. (I didn’t free it in the end…That’s the dirty part.
I did almost nothing about research this summer. I spent my first month in Europe, only to find that LU stuff had been done by Spanish collaborating groups. For the next two months, I work with an undergrad to reimplement my SC paper without the dependency of BLIS library (This is her summer intern project).
Today marks the end of the summer. The next week is the first week of the fall semester. Time flies. Originally I am targeting at PPOPP, with the deadline in the beginning of August. Later I had to skip. Now I am rushing towards IPDPS, with due in the middle of October. But there are only two months left, and I cannot get a performance number by now.
This is a difficult and turning point in my life. I am still in the grind of my PhD period. After the publication of my first paper, I have to maintain the publication record. It appears my advisor will not give me the same attention and support as the first paper, so I have to rely more on myself. I am trying my best efforts to polish up my written skills.
Sometimes I searched the research profile of my acquaintances. To my shock, they all managed to publish their papers and to keep their publication records. Some folks even have more than 4 first-author papers in top-tier conferences. Not to mention that they might have several papers in preparation or in submission in the queue. I felt much more pressure.
The only thing I can do to catch up is to work harder and harder. Life is short and valuable. Interference is disturbing and annoying. Every second counts. Stop complaining. Live your dream.
Believe me, James!
Why do I always choose to do something that doesn’t make sense? Looks like I cannot finish anything?
It is not true. You are picking something that your mentor doesn’t have expertise in. The reason is that you don’t master a key skill. When you mentor has that idea, he will not first consider you to implement that. Rather, he would prefer you to explore something any other student is also unfamiliar with. And to him, that is a method to maximize his output!
YOU NEED TO MASTER A KEY SKILL!
QUICK LEARNER!
FROM https://www.karlrupp.net/2013/06/cpu-gpu-and-mic-hardware-characteristics-over-time/
Recently I was looking for useful graphs on recent parallel computing hardware for reuse in a presentation, but struggled to find some. While I know that colleagues have such graphs and data in use in their presentations, I couldn’t find a convenient source on the net and finally ended up collecting all the data (again) and decided to make the outcome of my efforts available here. For that purpose, Wikipedia already provides extensive lists on AMD graphics processing units as well asNVIDIA graphics processing units. For CPUs I restricted my comparison to the family of Intel Xeon microprocessors supplemented by Intel’s export compliance metrics for Xeon processors for simplicity, as the main trend would also hold true for AMD processors.
My comparison considers high-end hardware available by the end of the respective calendar year. Multi-GPU boards are ignored because they only represent a small share of the market. Similarly, I only consider CPUs for dual socket machines, since this is also the baseline used by Intel for comparisons with their MIC platform (aka. Xeon Phi). Numbers for the Xeon Phi were taken directly from an Intel PDF on the Xeon Phi.
>> Download raw data, Gnuplot scripts and figures <<
First let us have a look at the number of processing elements or cores of GPUs and CPUs. For GPUs this is slightly ambiguous, as one might count thread work groups (also called streaming processors by NVIDIA) rather than individual threads, yet I used the latter since they better reflect the massively parallel nature of the architecture. Here is the chart for high-end hardware for single precision:
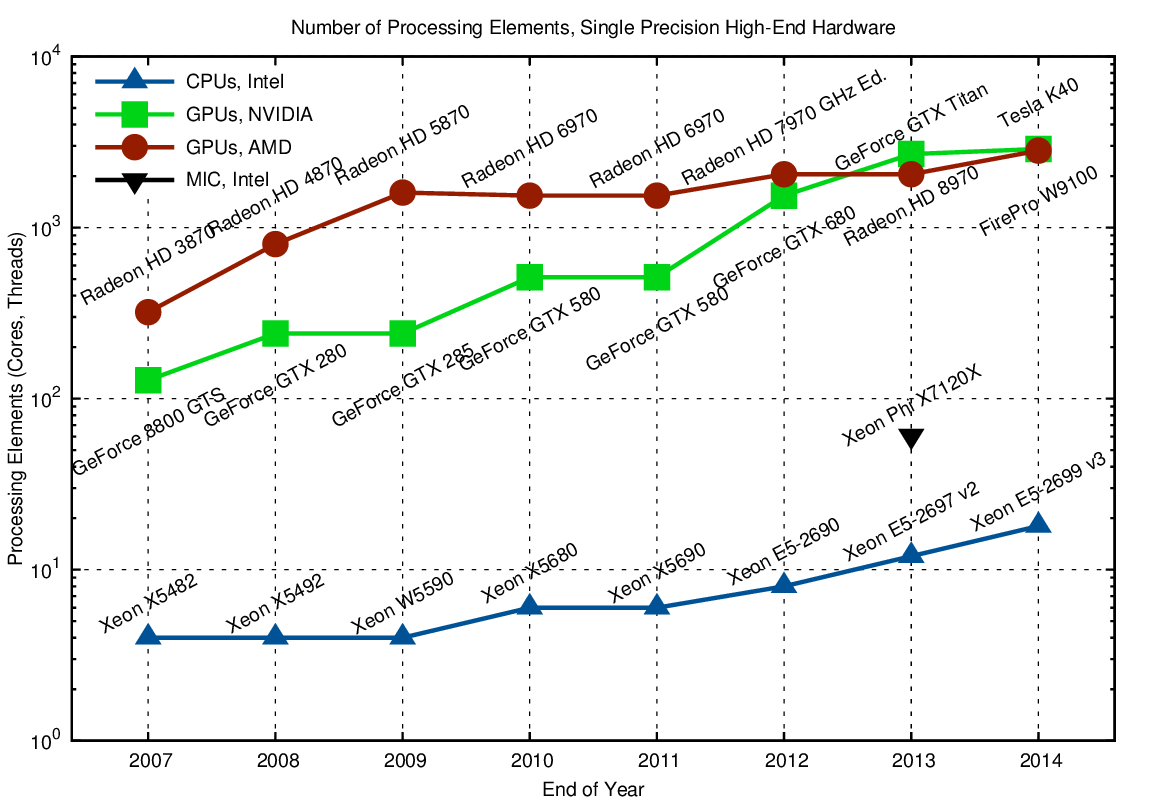
What is fairly remarkable is the two different strategies pursued by AMD and NVIDIA around 2009. AMD quickly ramped up to number of processing elements to 1536 in 2009, yet this number only increased mildly to 2048 in 2013. On the contrary, NVIDIA hardware used less hardware parallelism with 512 simultaneous threads in 2010 and 2011. However, their latest chips increased the core count up to 2688 on a GTX Titan. CPUs moved from four cores per socket in 2007 to eight cores per socket in 2012. The Xeon Phi with 61 cores is closing the gap between CPUs and GPUs and is thus a good candidate for applications with medium-grained – but not fine-grained – parallelism.
Since NVIDIA keeps their full double precision performance restricted to their Tesla products, we need a separate comparison chart here:
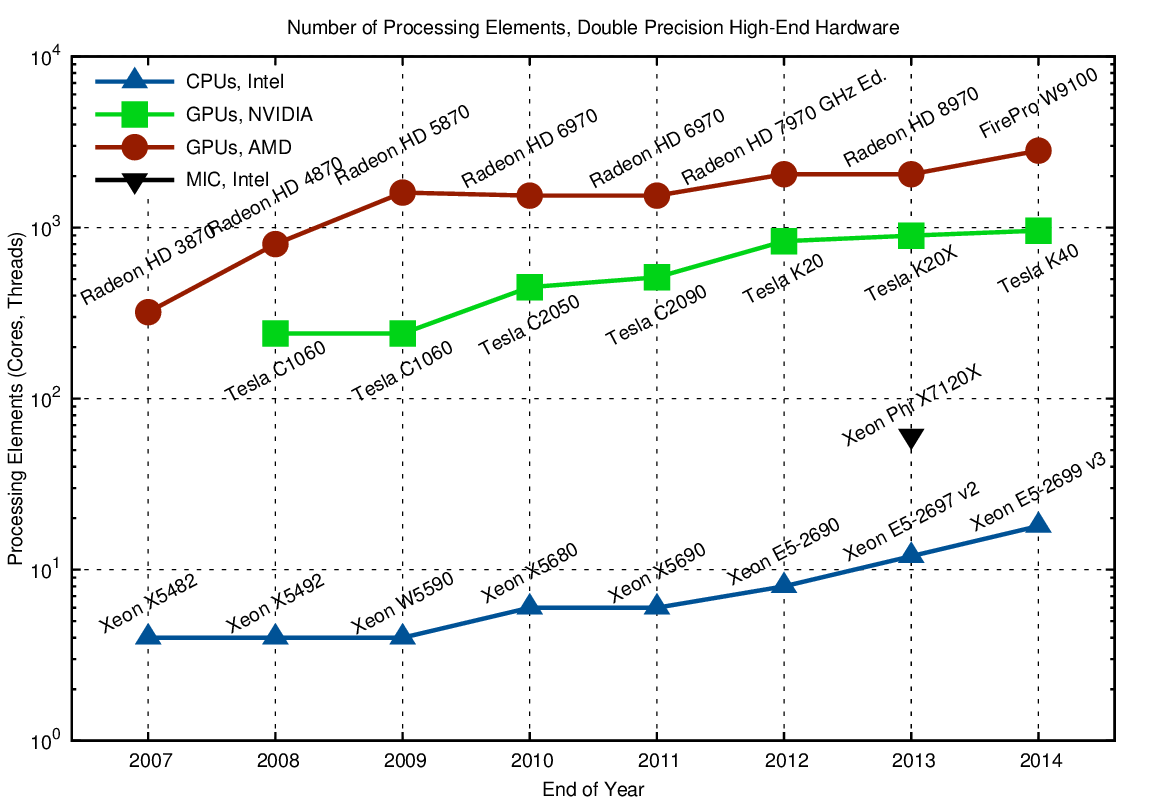
The data for Intel CPUs and AMD GPUs is the same as for the single precision case. It is interesting to see that the Tesla K20-series targeting general purpose applications does not show the same increase in the number of processing elements (896 for the K20X) as the consumer-line products GTX 680 and GTX Titan do. However, the internals are still comparable: There are 2688 single-precision processing elements on the K20X, which represent 896 units in double precision, i.e. four single precision units represent one double precision unit.
Since the main reason for the introduction of parallel architectures were power constraints, basically all architectures today are limited to about 250 Watts:
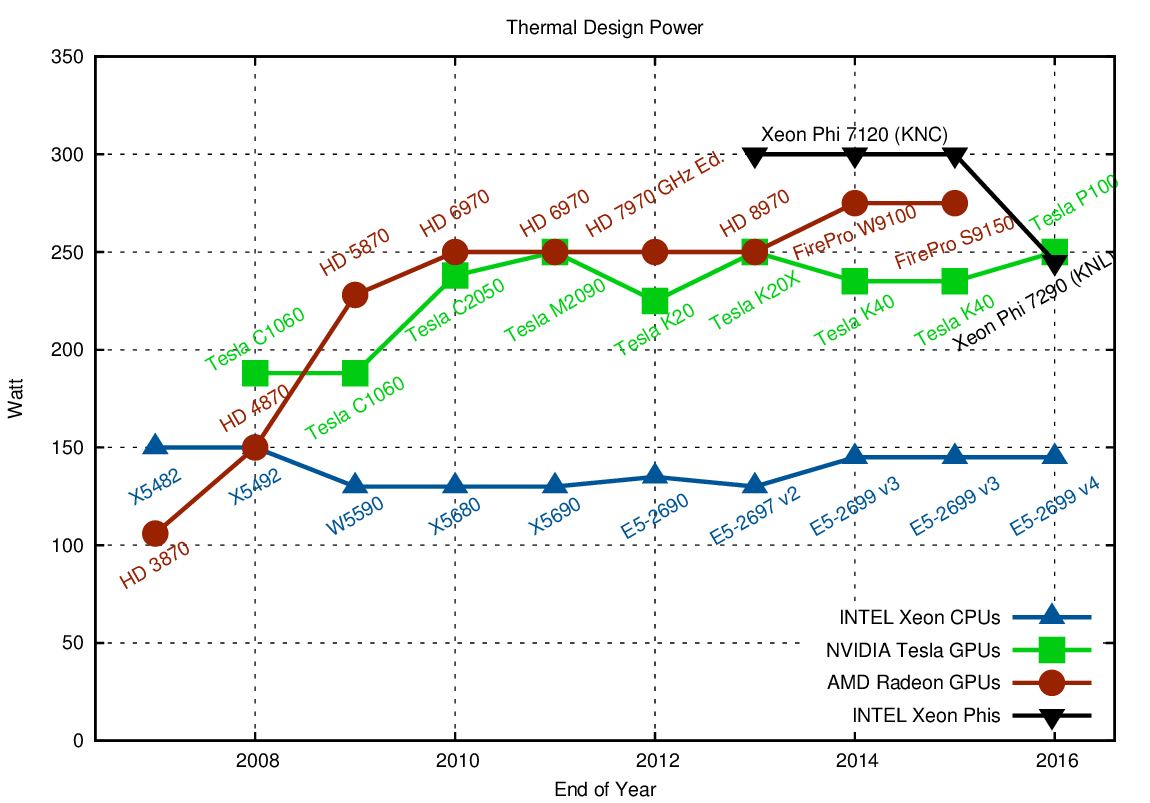
A fair comparison in terms of power and performance should be based on a dual socket system versus a single GPU
CPUs generally use only half the thermal design power (TDP) when compared to a single GPU, hence suggesting that a fair comparison in terms of power and performance should be based on a dual socket system versus a single GPU. It should also be noted that the peak performance consumption can sometimes exceed the TDP by a significant margin, as a number of reviews such as this comparison of a Radeon HD 7970, a Radeon HD7950, and a GeForce GTX 680 suggest. Dynamic clock frequency techniques such as those used for CPUs have recently been adopted by both GPU vendors as well and may further drive up the short-term power consumption. Consequently, the TDP plateau will remain at about this level, while power supplies are likely to increase their peak power output for some time in order to handle higher short-term power consumption. The Xeon Phi is in terms of power consumption no different than GPUs: Their 300 Watt TDP is probably just a little bit more frank than the 250+ Watt TDP specified for GPUs, but this is just my personal speculation.
Accelerators are – nomen est omen – great for providing high performance in terms of floating point operations (FLOP) per second. Consequently, it is no surprise that the effectiveness of GPUs for general purpose computations is often reduced to their pure FLOP counts, even though this may be the totally wrong metric as will be discussed in the next section.
Since NVIDIA provides dedicated product lines focusing on either single or double precision arithmetics, we consider the two separately, even though this would not be necessary for AMD GPUs and Intel CPUs. Let’s get started with single precision:
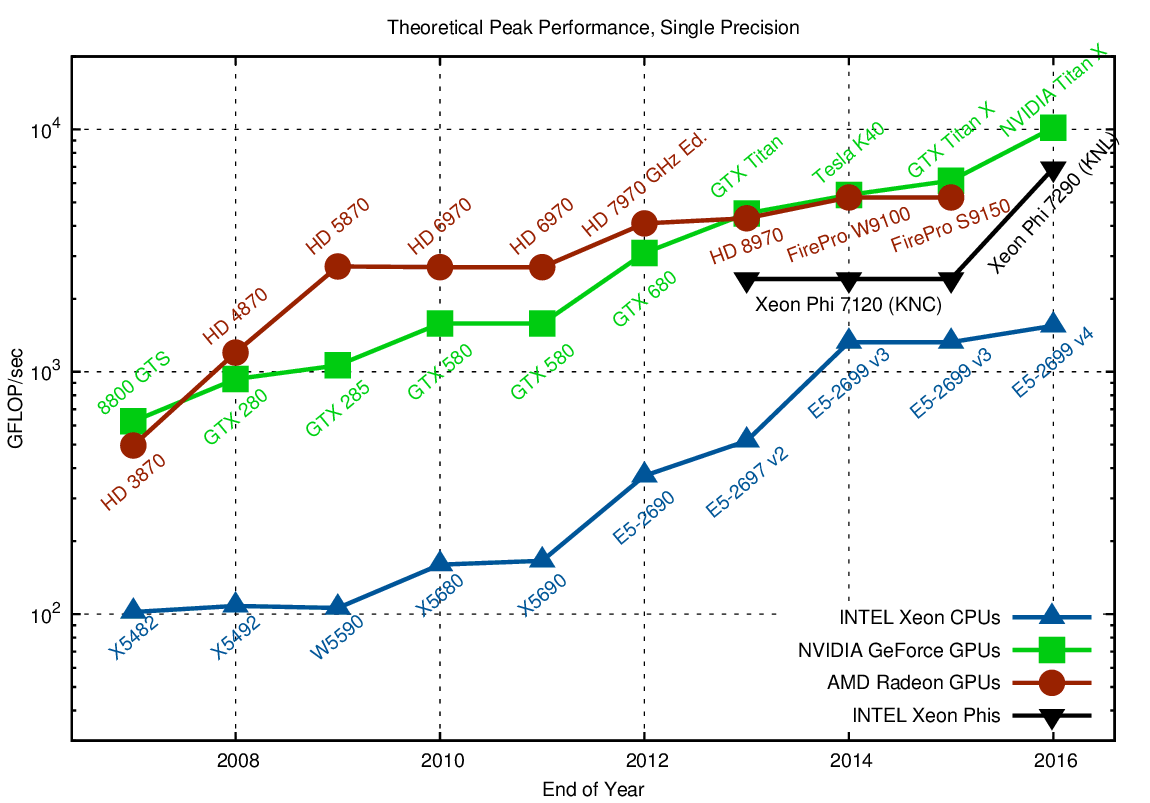
One can clearly see a five- to fifteen-fold margin when comparing high-end CPUs with high-end GPUs, which was particularly pronounced around 2009. The introduction of Xeon CPUs based on the Sandy Bridge architecture reduced the gap by a little, yet it is still a factor of five when comparing a single GPU with a dual-socket system. What is not entirely reflected in the chart is the fact that the theoretical peak on the GPU is harder to reach than for the CPU, but even when taking this into account the GPU is still faster by a significant margin. The Xeon Phi falls behind in terms of single precision arithmetics, yet this is not a major concern as the architecture aims at providing high performance using double precision arithmetics:
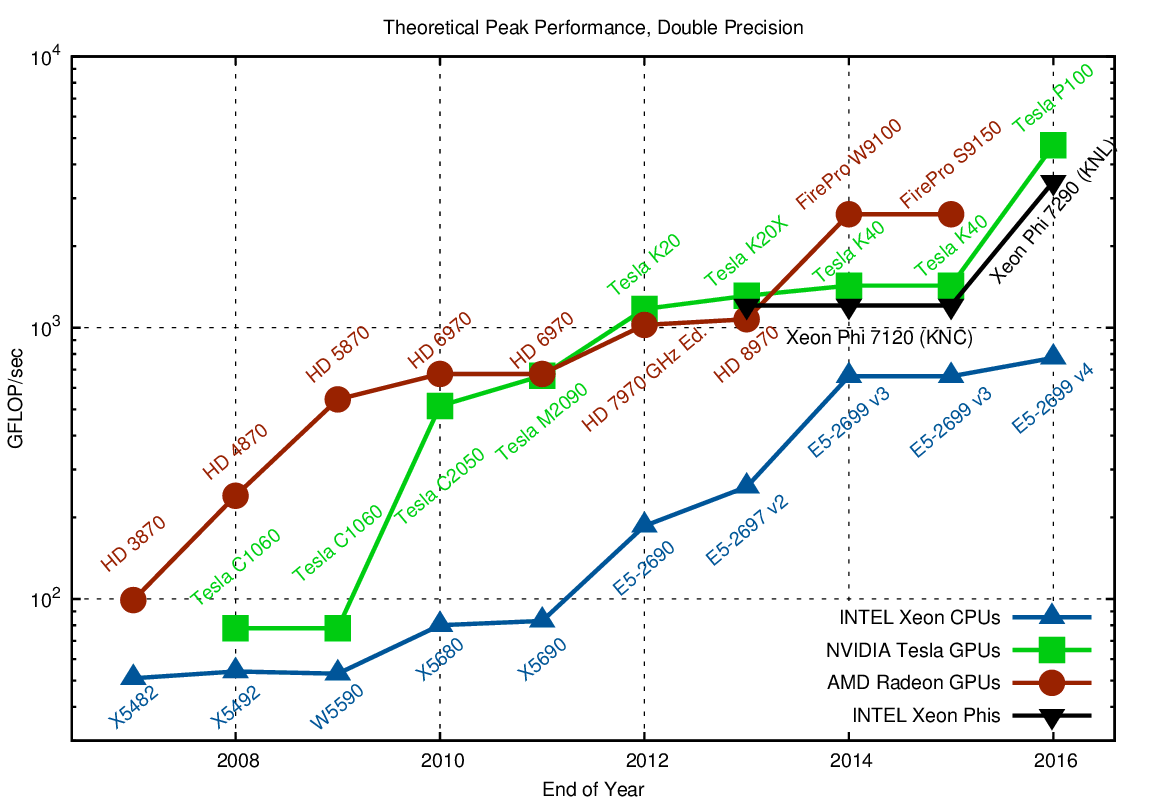
A preference of one architecture over another should be based on development effort, maintainability, and portability aspects
Current GPUs are usually able to provide only a quarter of their theoretical single precision peak performance, while the difference on the CPU is only a factor of two. What is also interesting to see is that GPUs were virtually unable to deal with double precision arithmetics before 2008, so it took until 2010 until one could see a significant theoretical gain over the CPU. Also, AMD had a good advantage over NVIDIA at that time, even though it was NVIDIA who pushed general purpose computations back then. Even today, a dual socket CPU-based system is within about a factor of three when it comes to theoretical double precision peak performance. All three accelerator architectures provide virtually the same peak performance, so a preference of one architecture over another should be based on development effort, maintainability, and portability aspects rather than minor differences in peak performance.
Since power is the limiting factor in computing today, let us have a look at FLOPs per Watt in both single and double precision:
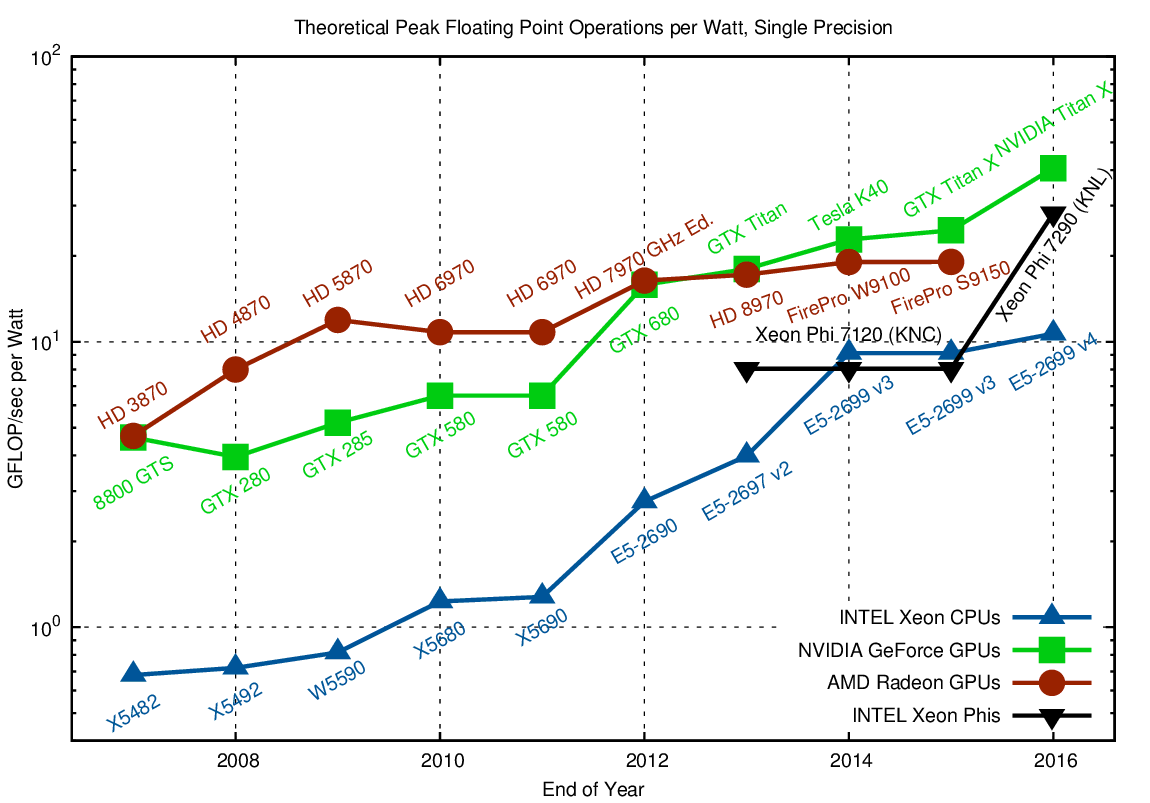
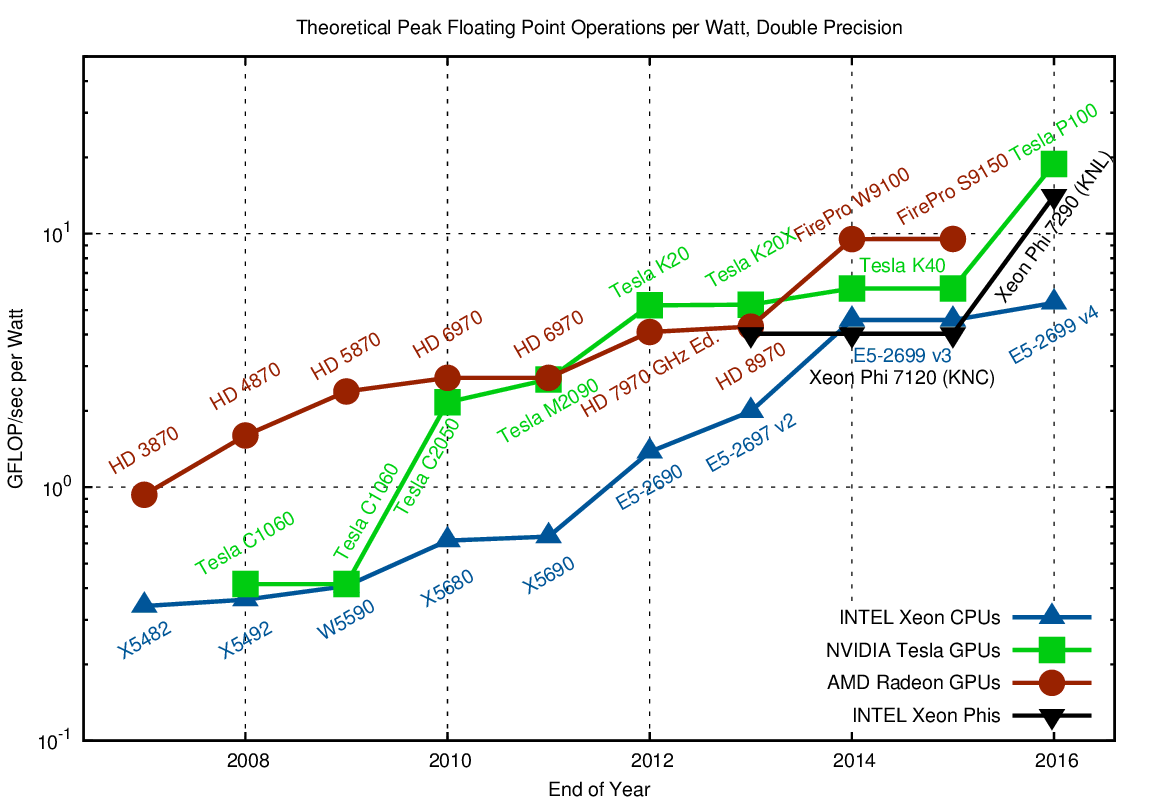
The efficiency gap is unlikely to increase in the future
Again, for a massively parallel algorithm with fine-grained parallelism such as dense matrix-matrix multiplications, accelerators provide about a five-fold advantage when compared to CPUs. The increase in power efficiency in 2013 over 2007 is a factor of four for both architectures, hence the efficiency gap is unlikely to increase in the future.
To close this section on raw performance, let us compare the floating point performance contributed by each processing element or core:
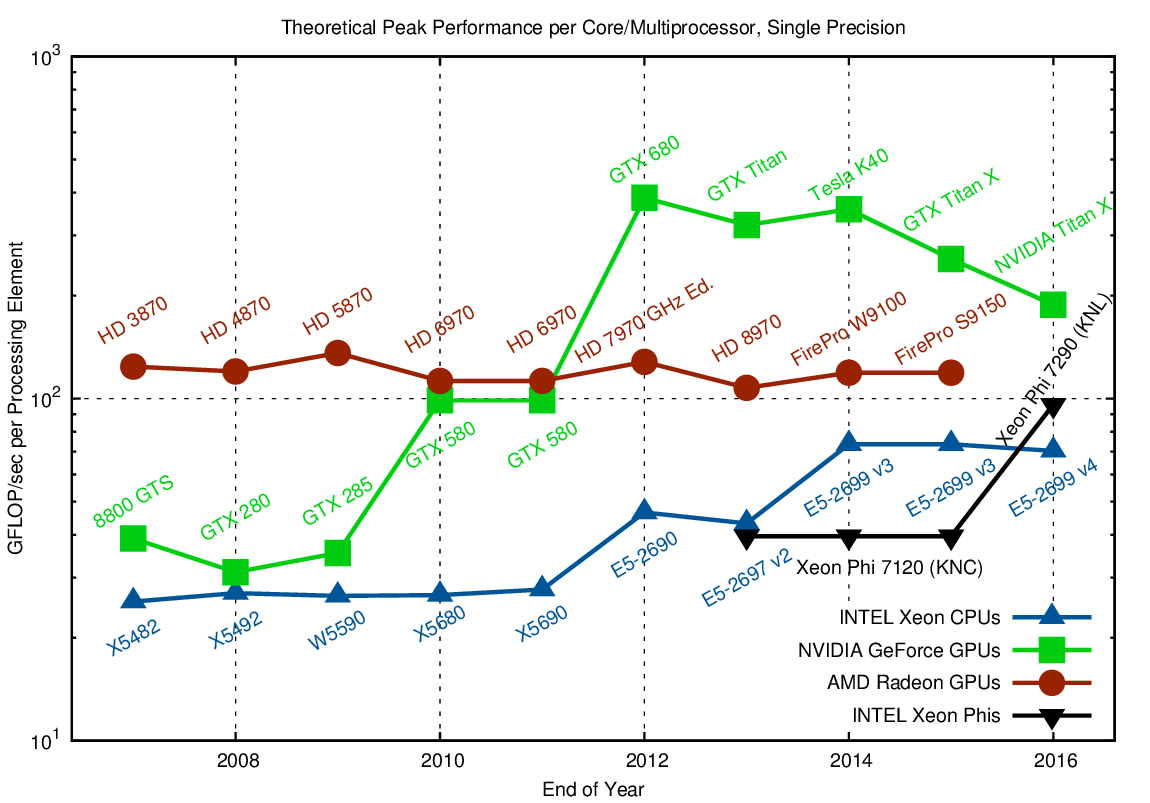
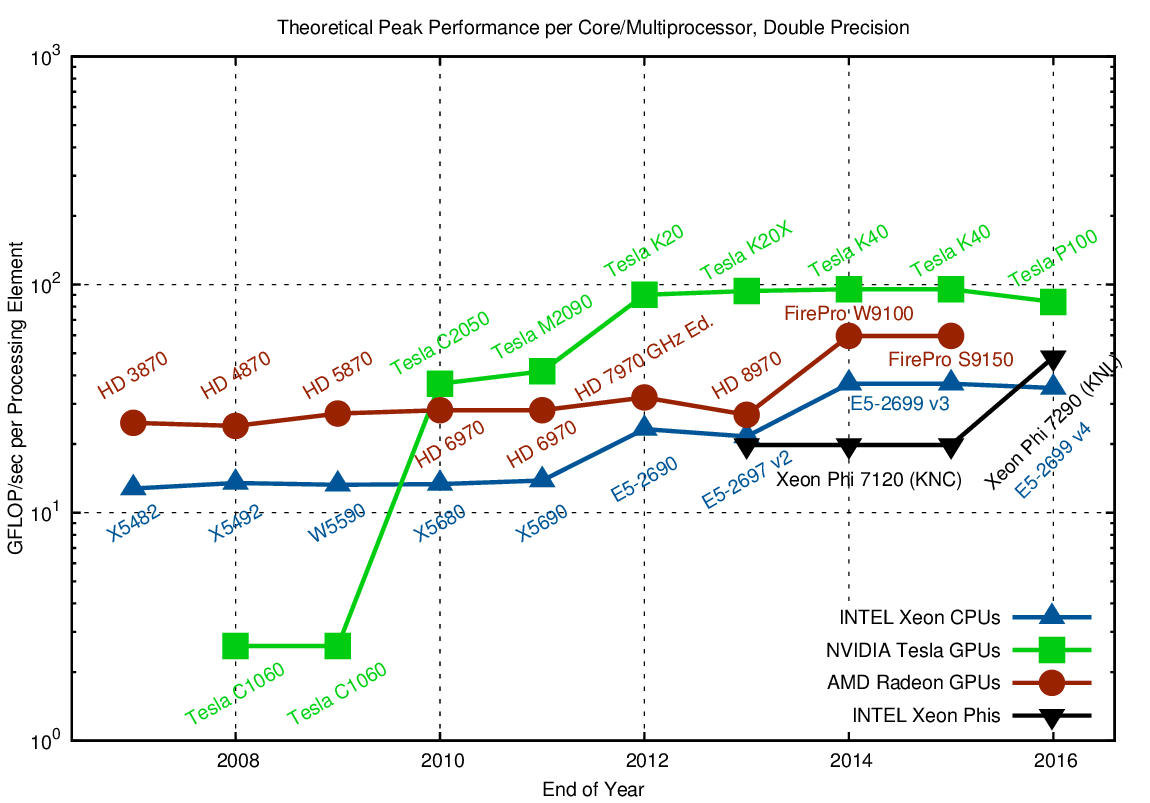
The sequential processing power of CPUs is about ten to twenty times larger than that of GPUs, reflecting their suitability for a much wider range of applications. It is also interesting to see that the recent leap in performance per core for Intel CPUs was only due to a change in the microarchitecture to Sandy Bridge. This includes additional vector instructions via AVX, which allow for processing multiple operands simultaneously if they are properly laid out in memory. Clearly, this is not a truly general purpose solution, thus confirming that sequential general-purpose performance stagnates and regular, vector-friendly data layout will become more important in the future.
The suggested good single-core performance of the Xeon Phi in the charts above was somewhat surprising to me, as it does not reflect my experiences with this platform. One of the reasons for the good performance per core certainly is due to the use of vector operations and that transistors have been spent on arithmetic units rather than caches and the like. Thus, based on the two charts one must not conclude that the Xeon Phi provides high sequential performance. Nevertheless, it is well reflected that the Xeon Phi is essentially a collection of CPU cores rather than a GPU-like architecture.
In order to use the arithmetic units efficiently, the respective data must be available in registers. Unless that is already available in cache, it needs to be loaded from global memory and eventually be written back at some later point. These loads and stores are a bottleneck for many operations, which CPUs to some extent mitigate by large caches. However, we will ignore any influences of caches and only compare memory bandwidth to global memory (see E. Saule et al. for a reference to the ring-bus bandwidth on the Xeon Phi):
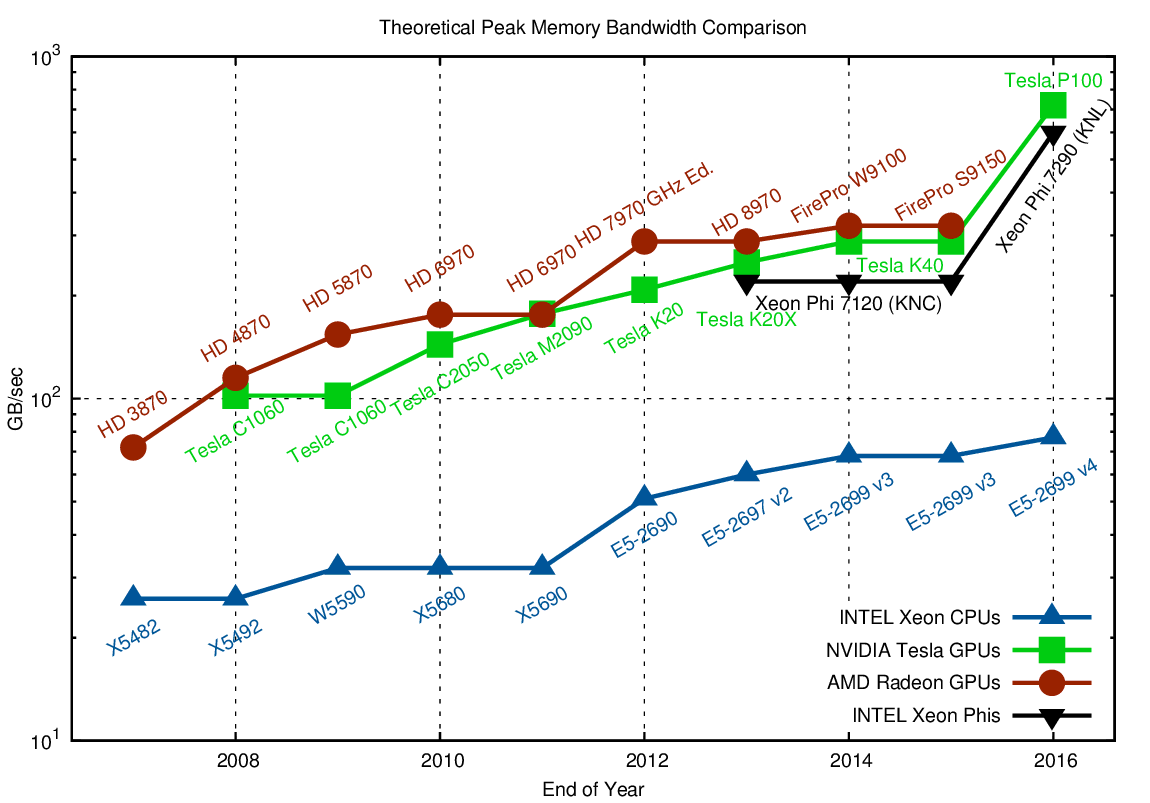
In contrast to raw performance, the advantage of accelerators over a single CPU socket in terms of peak memory performance has increased from about three-fold in 2007 to six-fold today. Using a second CPU socket and considering that peak memory bandwidth on GPUs requires very regular access patterns, the attractiveness of accelerators is considerably lower than for the FLOP-limited regime discussed in the previous section.
Also note that the increase in memory bandwidth from 2007 to 2013 was only two-fold for CPUs and three-fold for GPUs, mostly through additional memory channels or broader buses. With DDR4 SDRAM hitting the market soon, a further increase in memory bandwidth at about the same rate is to be expected.
There is also lot to be said and compared about caches and latencies, yet this is well beyond the scope of this blog post. What should be noted, however, is a comparison with PCI-Express memory transfer rates: A PCI-Express v2.0 slot with 16 lanes achieves 8 GB/sec, and up to 15.75 GB/sec for PCI-Express v3.0. This is at best comparable to a single DRAM-channel.
Whenever data needs to be loaded from global memory to feed the arithmetic units, a significant imbalance shows up, commonly referred to as the memory wall. For example, if you want to add up the numbers in two buffers of length N and store the result in a third buffer, all using double precision, you need to load 2N*sizeof(double) = 16N bytes from memory, and write N*sizeof(double) = 8N bytes back, using a total of N arithmetic operations. Ignoring address manipulations for loads and stores, only 1/24 FLOPs per transferred byte are required. Similarly, even operations such as dense and sparse matrix-vector operations are usually well below one FLOP per byte. Hence, higher FLOP per byte ratios indicate that an architecture can only be fully utilized by With this in mind, let us have a look at FLOP per byte ratios of high-end hardware:
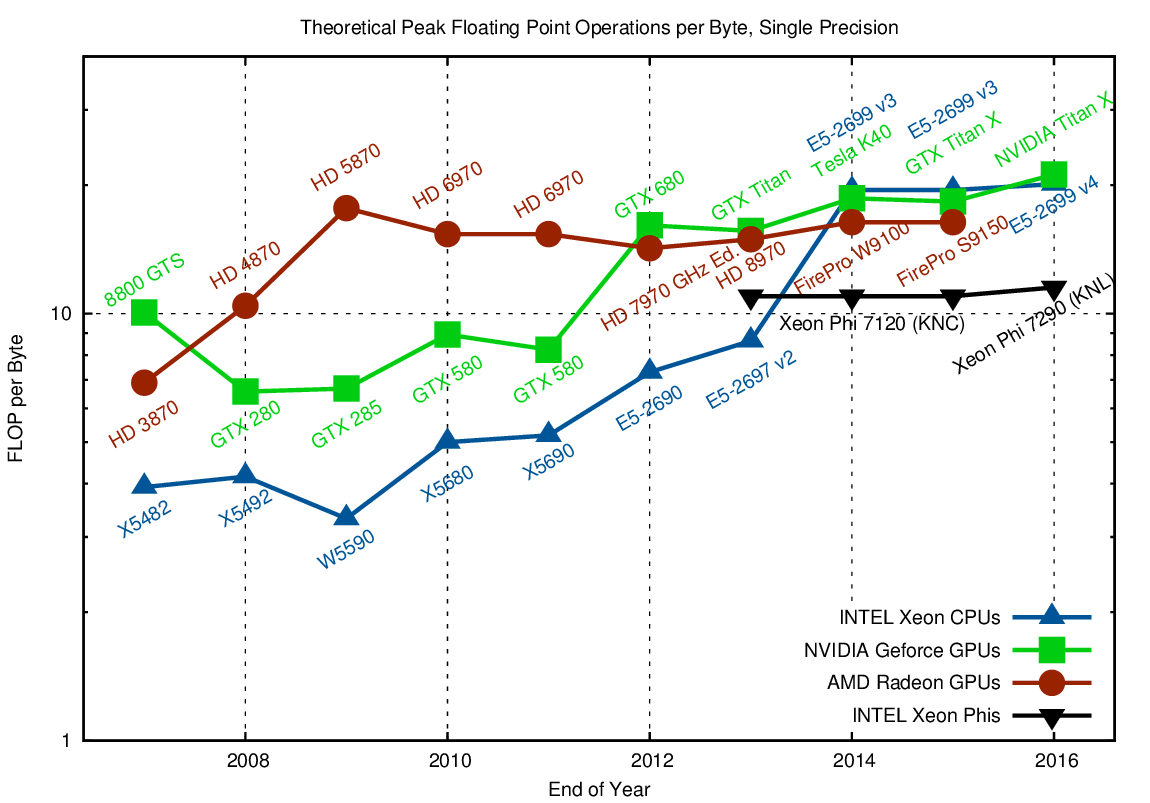
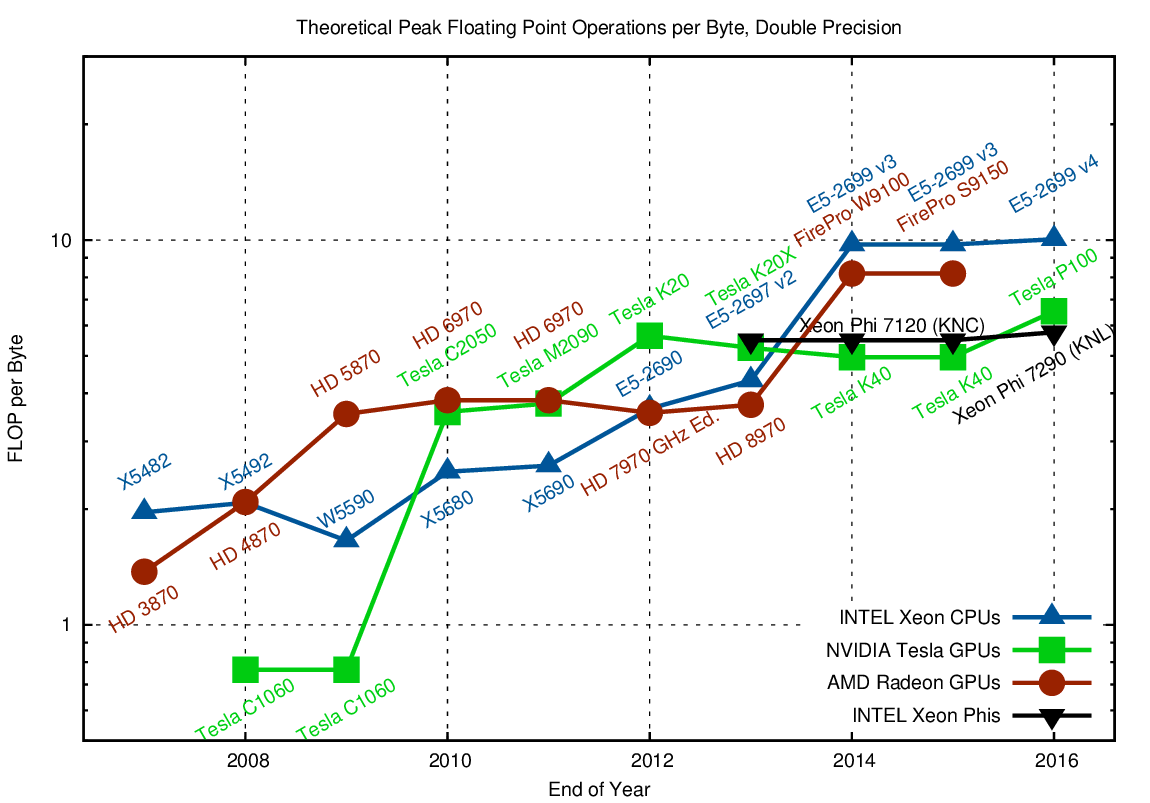
As can readily be seen, both CPUs and GPUs offer very high FLOPs per byte ratios. What is interesting to observe is the sharp increase for high-end AMD GPUs up until 2009, followed by a fairly flat plateau since then. This might serve as an indication that the range of suitable algorithms gets too small above 20 FLOPs per byte in single precision, or that the necessary caches get too expensive. This is definitely something to look at in future hardware generations.
FLOPs on GPUs are for free
Overall, the general guideline that FLOPs on GPUs are for freeapplies and will certainly continue to apply. Thus, the problem to tackle for future hardware generations is memory, not FLOPs. Another way to put it: Reaching Exascale is at least partially about solving the wrong problem.
The comparison of main hardware characteristics did not show any unexpected results: Accelerators are good for FLOP-intensive applications, but performance gains by much more than about an order of magnitude over a comparable CPU are certainly not backed up by the hardware facts. It will be interesting to see how the FLOP per byte ratio will develop in the near future, as the raw processing count keeps increasing at a higher pace than the memory bandwidth. Also, I’m looking forward to a tighter integration of traditional CPU cores with GPU-like worker units, possibly sharing a coherent cache.
The following zip archive contains text files with the raw data, all the Gnuplot scripts for the figures, and a Bash script for generating them all with a simple call. All content is available via a permissive license so that you can reuse the plots in reports, alter as needed, etc.:
>> Download raw data, Gnuplot scripts and figures <<
Edit, June 24th, 2013: As Jed Brown noted, GFLOP/sec values for CPUs were missing a factor of two due to a single- vs. double-precision lapse. This is now corrected. Thanks, Jed!
Edit, June 13th, 2014: Updated graphs and text to consider Intel CPUs available by the end of 2013.
Edit, March 25th, 2014: Updated graphs and text for hardware available by the end of 2014.
From http://www.thegeekstuff.com/2012/04/route-examples/
Let us use the following sample network architecture for the rest of the examples.
In the diagram below, we have 2 individual networks ( 192.168.1.0 and 192.168.3.0, with subnet mask of 255.255.255.0 ).
We also have a “GATEWAY” machine with 3 network cards. 1st card is connected to 192.168.1.0, 2nd card is connected to 192.168.3.0, and the 3rd card is connected to the external world.

Now we need to add a routing entry such that we are able to ping 192.168.3. series ip-addresses from 192.168.1. series. The common point we have is the GATEWAY machine.
So, on each machine in 192.168.1.* network a default gateway will be added as shown below.
$ route add default gw 192.168.1.10
Now when 192.168.1.1 pings 192.168.3.1, it will go to the GATEWAY via 192.168.1.10.
In GATEWAY, add the following routing entry.
$ route add -net 192.168.3.0 netmask 255.255.255.0 gw 192.168.3.10
Now all the packets addressed to 192.168.3.* network will be forwarded via the 192.168.3.10 interface, which then delivers the packets to the addressed machine.
It is very similar to what we did earlier.
So, on each machine in 192.168.3.* network a default gateway will be added as shown below.
$ route add default gw 192.168.3.10
In GATEWAY, add the following routing entry.
$ route add -net 192.168.1.0 netmask 255.255.255.0 gw 192.168.1.10
Now 192.168.3.* machines can ping 192.168.1.* machines.
In the previous two example, we have interconnected the 2 different networks.
Now we need to access the internet from these 2 different networks. For that, we can add a default routing ( when no routing rule matches ) to the 125.250.60.59 which is connected to the external world as follows.
$ route add default gw 125.250.60.59
This is how it works:
From http://elinux.org/Jetson/Remote_Access
Note: You might need to change “wlan0” (your network device that has internet) and “eth0” (you local network device that has the Jetson board) for your computer setup.
Put this into a new file named “share_my_internet.sh”:
#!/bin/sh # Share one network's internet connection with another network. # eg: If your Wifi adapter with internet is called wlan0 # and your local Ethernet adapter is called eth0, # then run: # ./share_my_internet.sh wlan0 eth0 # This will only last until you reboot your computer. sudo iptables --flush sudo iptables --table nat --flush sudo iptables --delete-chain sudo iptables --table nat --delete-chain sudo iptables --table nat --append POSTROUTING --out-interface $1 -j MASQUERADE sudo iptables --append FORWARD --in-interface $2 -j ACCEPT sudo sysctl -w net.ipv4.ip_forward=1
Then make that script an executable:
chmod +x share_my_internet.sh
Now you can run it, passing first the name of your internet adapter (eg: wlan0) and your local network adapter (eg: eth0):
./share_my_internet.sh wlan0 eth0
(You will need to execute this script again if you reboot your desktop computer, so you might want to add something like “~/share_my_internet.sh wlan0 eth0” to the bottom of your “~/.bashrc” login script so it gets executed automatically).
If you are using a graphical desktop environment and thus you killed NetworkManager earlier, now you should re-start NetworkManager to give you back your regular internet:
sudo service networking start sudo service network-manager start
Bring up the local network using the first IP address:
sudo ifconfig eth0 up 192.168.1.100 netmask 255.255.255.0
Now your device should have internet access!
